uni2ascii en ascii2uni skakel tussen UTF-8 Unicode en enige van 'n verskeidenheid van 7-bit ASCII ekwivalente insluitend: heksadesimale en desimale HTML numeriese karakter verwysings, u-ontsnappings, standaard heksadesimaal, en rou heksadesimale.
Sulke ASCII ekwivalente is nuttig wanneer insluitend Unicode teks in program bron wanneer teks aangaan Web programme wat die Unicode karakter stel kan hanteer, maar is nie 8-bit veilig, en wanneer debugging.
Die Unicode ontsnap beskikbaar is:
- HTML heksadesimale numeriese karakter verwysings (bv)
- HTML desimale numeriese karakter verwysings (bv ȳ)
- U-ontsnappings, soos gebruik in Python (bv u00E9)
- U-ontsnappings in die BMP en U-ontsnappings buite die BMP, bv u00E9 maar U00010024.
- U -escapes (bv U 00E9)
- U-ontsnappings (bv U00E9)
- U-ontsnappings (bv u00E9)
- U-ontsnappings binne hoek tussen hakies (bv)
- X-ontsnappings (bv x00E9)
- X-ontsnappings met draadjies (bv x {} 00E9)
- Standard heksadesimale (bv 0x00E9)
- Rou heksadesimale (bv 00E9)
uni2ascii aanvaar 'n command line vlag te bepaal of om hoofletters AF of laer-geval af te genereer as heksadesimale syfers aangesien sommige paar programme aanvaar slegs die een of die ander. ascii2uni aanvaar nie.
In die geval van uni2ascii by verstek word slegs karakters buite die ASCII reeks omskep. Selfs as ASCII karakters word ook omskep word newlines bewaar, tensy hulle bekering uitdruklik versoek word. Ruimte karakters word ook bewaar tensy omskakeling uitdruklik versoek word. In die geval van die drie nie-ASCII karakters ruimte (Etiopiese woord ruimte, Ogham ruimte, en ideografiese ruimte), indien ruimte karakters nie omgeskakel is, word dit vervang met ASCII ruimte (0x20) om die uitset binne die 7- hou bietjie ASCII-reeks.
Hierdie pakket bevat vier programme. Die hoofprogram is uni2ascii. Dit is geskryf in C en moet saamgestel. uni2html.py is die voorloper van uni2ascii. Soos geskrywe is in Python, beteken dit nie nodig het om te word opgestel en moet loop op net oor enige huidige rekenaar. uni2ascii is anders beter in dat:
- Dit genereer 'n groter verskeidenheid van uitvoer formate.
- Dit is ongeveer 20 keer vinniger.
- Dit hanteer insette in die volle 32 bit Unicode-reeks. In teenstelling, uni2html net die handvatsels
Basiese Veeltalige Vliegtuig (Vliegtuig 0), want op die oomblik Python verteenwoordig Unicode geënkodeerde teks intern gebruik van 16-bit heelgetalle. As jy die teks in, sê, Lineêre B of Ugarities het, uni2ascii nodig.
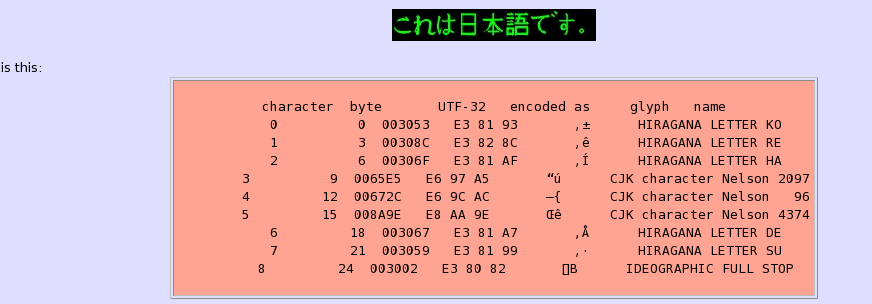
Dit doen 'n beter werk van verslagdoening foute. As dit 'n fout in sy insette, ontmoetings soos-mal gevorm UTF-8, is dit verslae van die ligging van die fout, beide in terme van die telling karakter van die begin van die lêer (begin by 0) en in terme van die telling byte van die begin van die lêer (ook begin by 0). (Character tellings en byte tel is oor die algemeen nie dieselfde aangesien 'n UTF-8 geïnkripteer karakter beslaan van een tot vier grepe.) Slegs die Python weergawe verslae die karakter tel. uni2ascii verskaf ook inligting oor die aard van die fout.
Die derde program, ascii2uni, is die omgekeerde van uni2ascii. Dit aanvaar teks wat 'n verskeidenheid van ASCII voorstellings van Unicode-karakters en genereer UTF-8 Unicode.
Die vierde program, ascii2uni.py, lees 7-bit ASCII met-u ontsnap Unicode, soos gebruik in Python en Tcl, en vat dit na UTF-8 Unicode. Dit is die oorspronklike program wat ascii2uni is 'n veralgemening
Wat is nuut in hierdie release:.
- Vaste fout in uni2ascii in wat in sekere gevalle die telling substitusie te hoog was, vas Debian fout # 626268.
- gelapte tot situasie in NetBSD wat getline ontbreek hanteer.
- uitgeklaar semantiek van suiwer opsie as die omskakeling van die karakters in ascii reeks behalwe ruimte en newline. Vaste fout in wat dit was nie korrek geïmplementeer vir tipe UTF8.
Wat is nuut in weergawe 4,17:
- Bygevoeg na die volgende omskakelings na die naaste ascii ekwivalent uni2ascii: U 2022 koeël "O", U + 00B7 middel dot tydperk, U + 0085 volgende lyn na newline, U + 2028 reëlskeiding om newline.
Wat is nuut in weergawe 4,16:
- Die Q-formaat werk weer in ascii2uni .
- Added U + 2033 DOUBLE PRIME om die karakters omgeskakel na hul naaste ascii ekwivalent onder die gebruik van die e-formaat in uni2ascii.
Wat is nuut in weergawe 4,15:
- Herdoop endian.h om u2a_endian.h tot konflik met skakel eksterne endian.h.
- verwyder afskrif van GNU getline van ascii2uni.c soos dit is standaard van POSIX2008.
Wat is nuut in weergawe 4,14:
- Vaste 'n fout wat ingemeng het met die gebruik van die Q-formaat in uni2ascii.
- Vaste fout in wat ascification van U + 2502 en U + 2503 dubbel kwotasie bygevoeg uitset.
- Vaste 'n fout in wat -A S opsie gegenereer a & quot; Omgeskakel so baie karakters & quot; lyn vir elke karakter as gevolg van laat in debugging kode.
Wat is nuut in weergawe 4,13:
- Vaste fout wat veroorsaak het dat oormatige aantal karakters verander na ASCII om gerapporteer word.
Wat is nuut in weergawe 4,12:
- Beide programme nou toelaat dat die naam insette lêer word gespesifiseer die opdrag lyn sonder verwysing.
Wat is nuut in weergawe 4,11:
- Hierdie vrystelling voeg ondersteuning vir die & lt; XX & gt; & lt; XX & gt; en% uXXXX formate.
Wat is nuut in weergawe 4,10:
- Hierdie vrystelling is vasgestel 'n fout wat die Y argument aan die -a vlag van ascii2uni 'n no-op, en stel die man bladsye en help om vir die Y en Q argumente na die a flag vir beide programme.
- Die Y argument is nou 'n fout vir uni2ascii.
- Die weergawe inligting en optrede is meer insiggewend.
Opsommings
Kommentaar nie gevind